

{kind=link}
Everything has a cost. Everything has a benefit.
Introduction
The story of the last few months at Delphos Labs is one of both stability and acceleration. On the one hand, we haven’t seen any major changes in the basic story of how software develops. Everyone is heavily using agents at this point, though surfaces differ; I prefer OpenCode and spend almost all day in it, while there are still some Claude Code fans and a few team members who look at the code in an IDE. On the other hand, our capabilities, throughput, and degree of automation continue to accelerate. The basic software development workflow is close to automatic for the class of tasks we throw at it. We have an agentic development loop that reads the task, gathers context, writes tests, implements, and commits; essentially tripling the rate at which PRs get written, with no changes in headcount. You can get almost everything done with a single command: “Agent, do work.”
The friction didn’t disappear, though. It moved.
On the days that I get to be an IC, I spend all day babysitting tmux tabs. There are a few flavors of these sessions. Take code reviews. I do about twenty or so a day, context-hopping between agent summaries, reading proposed comments, and rendering verdicts. We built an automated review loop with specialized subagents for security, architecture, test coverage, and comment accuracy, and it works well. But the bottleneck is no longer code production; it’s my attention. The new friction is reading the output, making the judgment calls, resolving the human-in-the-loop moments that the agents surface for me. When writing code, the workflow is different but the pattern is the same: I scan the acceptance criteria for the issue, skim the tests from our test-driven development agent, spot-check code as it’s being written, ask probing questions when something looks off, file follow-up issues, make sure tests pass in CI, and run the loop to automatically resolve PR comments. The time cost shifted from producing code to evaluating it. A Harvard Business Review study tracked roughly 200 employees over eight months and found the same pattern at scale: AI didn’t reduce their work, it intensified it through increased multitasking, workload creep, and the collapse of natural stopping points. A follow-up piece on “brain fry” documented the cognitive load that sustained AI use creates. Human attention isn’t just scarce; it depletes.
As I am feeling these new frictions, I’ve spent the last few months reading dozens of versions of the abundance argument. More software is getting written, and written faster, than ever before. The costs of a software project are coming down. And the whole thing feels overwhelming. A new vocabulary is forming around it: Jevons Paradox for software, lights-out codebases, the death of pull requests, outcome engineering, structural economic change, vibe coding in production. Jevons Paradox is the oldest and most useful of these frames. In 1865, William Stanley Jevons observed that more fuel-efficient steam engines didn’t reduce coal consumption; they increased it, because cheaper production made new applications economical and demand expanded to swallow the savings. The same dynamic is playing out in software right now. They all describe pieces of what I’m living. But none of them give me the tools to answer the question I face every morning: which frictions should I try to eliminate, and which frictions are actually load-bearing?
That’s what risk-return analysis is for. Everything has a cost and everything has a benefit, and when the cost structure changes, you don’t just do the same thing cheaper; you rethink what’s worth doing at all. In software engineering, human time is the common currency. Google’s internal cost accounting converted compute into SWE-equivalent hours. Brooks’s The Mythical Man-Month built an entire theory of project management around the irreducibility of human time. If human time is what we’re spending, then the question becomes where to spend it. For each phase of the software development lifecycle, I want to ask three questions: what does it cost in human attention, how does that cost distribute, and how do the benefits scale?
The Model
As we seek to deliver the most value for an organization, we inevitably run into the limits of human time and attention. When I say a phase “costs” something, I mean it draws down the finite judgment budget you carry into a workday. When I say a benefit “scales,” I mean the return on that draw grows, shrinks, or compounds depending on where you spend it. Every other decision in this framework flows from that scarce resource.
When AI makes software abundant, costs separate into two categories with fundamentally different behavior. Thin-tailed costs are normally distributed: broken dev environments, formatting errors, routine bugs, boilerplate. As AI capability increases, these get driven toward zero. The time between discovering one of these issues and resolving it collapses; the agent fixes it almost as fast as you notice it. Think of them as residual errors in a regression model shrinking as you add data. Downside is bounded and self-correcting. This is where the productivity story lives, and it’s real.
Fat-tailed costs follow a power law: security vulnerabilities, architectural debt in core systems, wrong product strategy. These do not shrink with abundance. They may grow, because more software means more attack surface, more code nobody fully understands, more places for catastrophic failures to hide. Downside is unbounded. A single breach can cost more than all productivity gains combined.
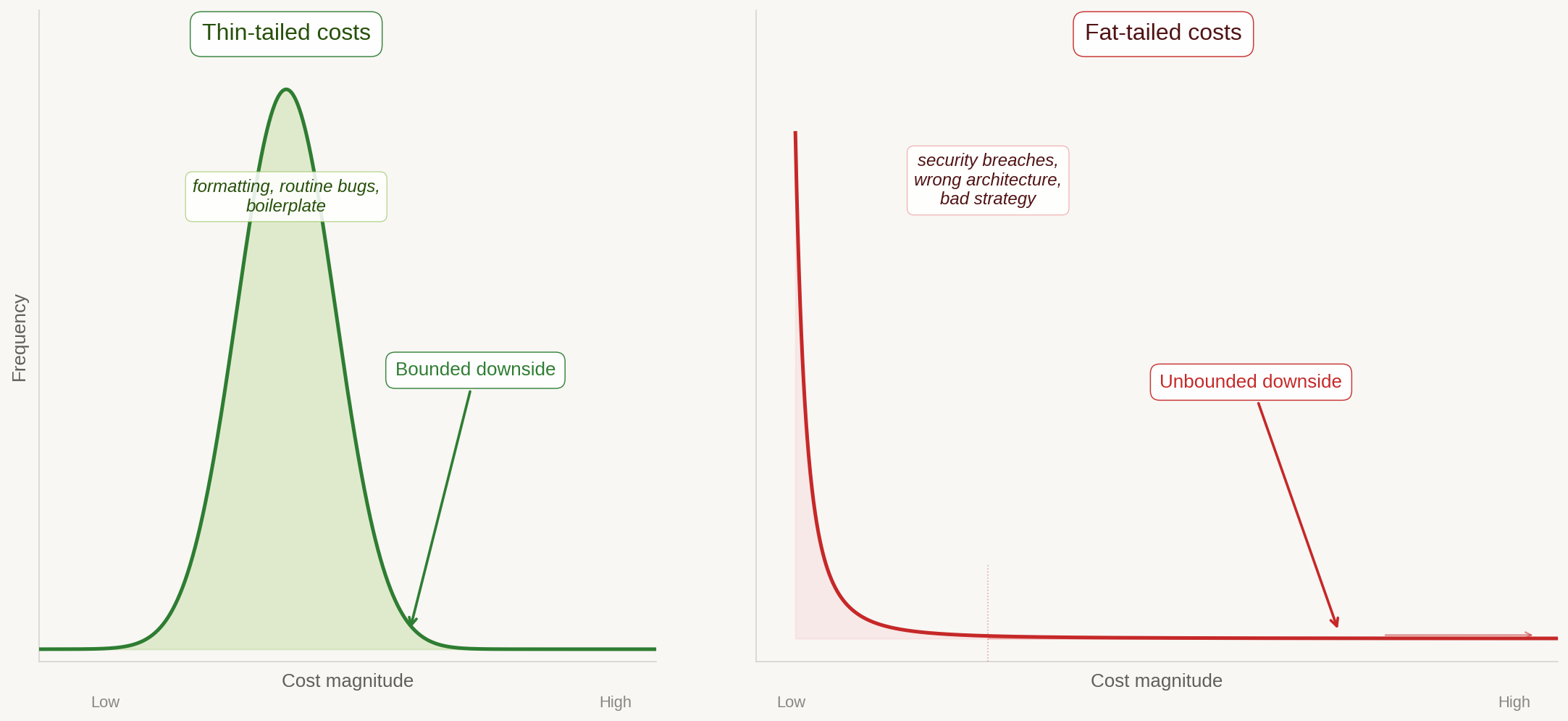
Thin-tailed costs shrink toward zero with AI. Fat-tailed costs have unbounded downside and don’t shrink with abundance. Image: Claude Opus.
The regression analogy goes deeper than it might seem at first. Adding more data to a well-specified model drives the normally distributed errors toward zero; but outliers, misspecification errors, and adversarial inputs are fat-tailed. No amount of data fixes a fundamentally wrong model. The same holds for software. No amount of AI-generated code fixes a fundamentally wrong architecture or a security vulnerability that an attacker finds first.
The other axis captures what happens when you invest more human time in a given phase, because the returns scale differently depending on where that time goes.
Some returns are sub-linear: they diminish. Commodity features, test coverage beyond a threshold, documentation for stable systems. The tenth login flow is worth less than the first, and each additional unit of effort yields less value than the one before it. Other returns are linear, staying constant and proportional: routine bug fixes, deployment frequency improvements, per-service monitoring. And some returns are super-linear: they compound. Shots on goal for product-market fit fall here, where Erik Schluntz argues that collapsing two-year architecture cycles to six months means “four times as many lessons in the same calendar time.” Security posture belongs here too, because it insures against increasingly large tail risks. Core architecture quality exhibits network effects because everything depends on it. Specification quality compounds as good patterns breed better patterns. And team learning velocity is itself super-linear; the meta-skill of rapid iteration accelerates everything downstream.
Cory Ondrejka, in his Outcome Engineering manifesto, captures why this framework matters for software specifically: “In an agentic world, code is the cheapest resource. Build to answer questions. Build to test hypotheses. Build to inform debates openly. Build the things you used to buy so you can prove they work perfectly for you.” When building is that cheap, the interesting question is no longer how much something costs to produce. It’s how the costs distribute and how the benefits scale across every phase of the software development lifecycle. Cross the two axes and you get what I’ll call the risk-return framework for the rest of this essay: classify each phase by its cost distribution and benefit scaling, and the framework tells you where to spend human time.
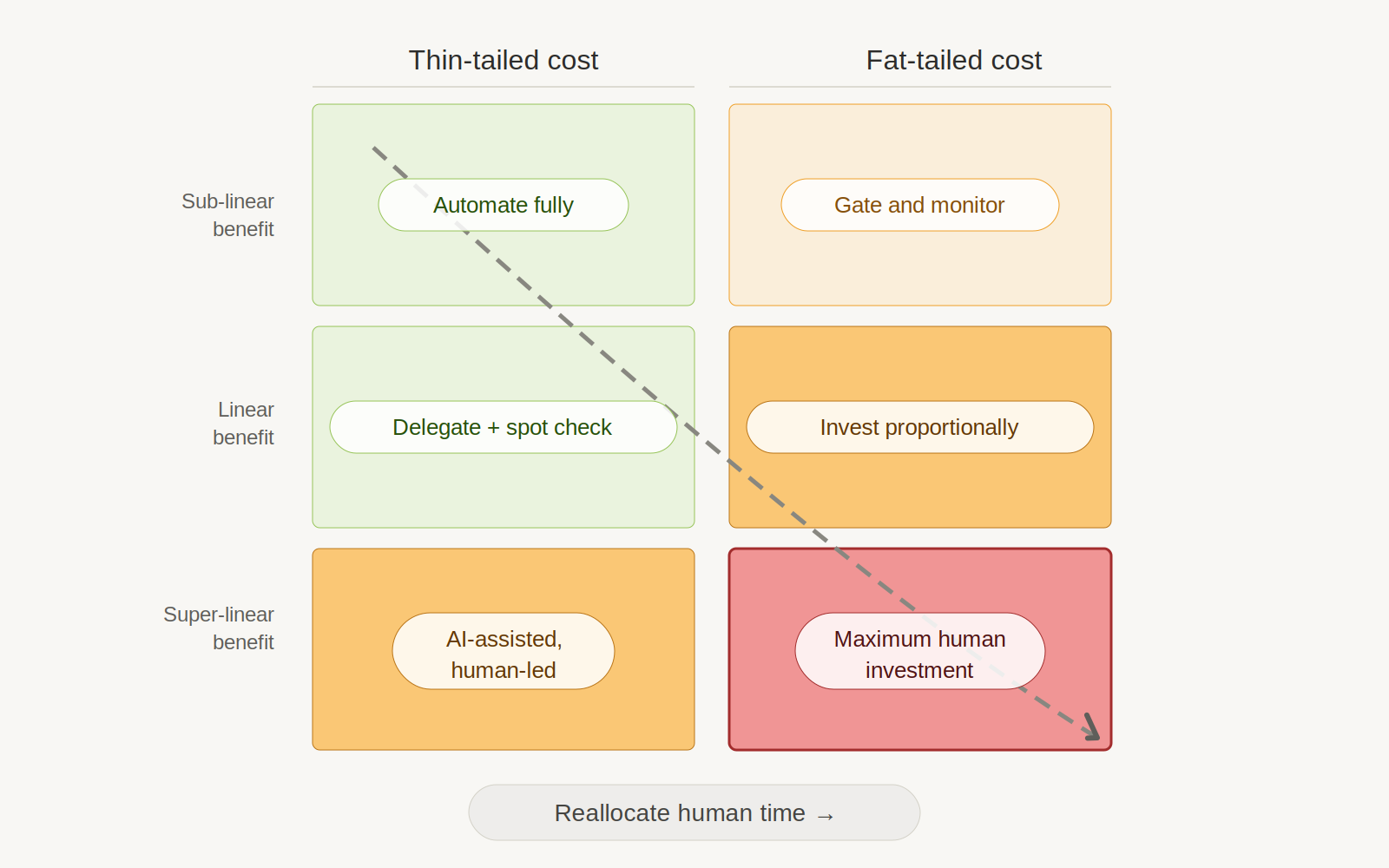
The risk-return framework. Classify each SDLC phase by cost distribution and benefit scaling. The arrow shows the reallocation direction that abundance demands. Image: Claude Opus.
| Thin-tailed cost | Fat-tailed cost | |
|---|---|---|
| Sub-linear benefit | AUTOMATE FULLY | GATE AND MONITOR |
| Linear benefit | DELEGATE + SPOT CHECK | INVEST PROPORTIONALLY |
| Super-linear benefit | AI-ASSISTED, HUMAN-LED | MAXIMUM HUMAN INVESTMENT |
The top-left quadrant is formatting, boilerplate, commodity features; don’t spend human time. The bottom-right is core architecture, security, product strategy, threat modeling; this is the highest-leverage work a human can do.
The reallocation principle follows directly: AI makes it possible to shift human time from top-left to bottom-right. Abundance makes it urgent, because the fat-tail surface area grows with volume.
One nuance the framework doesn’t capture on its own: some phases have split profiles. TDD is cheap to execute but catastrophic to skip. Monitoring costs little to run but insures against unbounded downside. These phases earn their quadrant placement from the cost of omission, not the cost of execution. A reader applying the framework mechanically would place TDD in the top-left and automate it fully. That would be a mistake. When you see a phase with thin execution cost but fat omission cost, invest as if it belongs in the bottom-right.
The Software Development Lifecycle (SDLC)
Now that we have a framework of costs and benefits, we need something to operate on. The software development lifecycle is the standard term for the full sequence of activities that take a piece of software from conception to retirement, formalized in standards like ISO/IEC 12207 and NIST SP 800-64. In practice, the SDLC is less a strict sequence than a set of nested loops running at different cadences.
The DevOps community often describes these as the inner loop and the outer loop. In the standard usage, the inner loop is the developer’s local cycle of editing, building, and debugging; the outer loop is CI/CD, deployment, and production monitoring. I’m borrowing the framing but extending it. In this essay, the inner loop covers the full task-level cycle: task definition, test-driven development, implementation, review, and commit. The outer loop covers the product-level cycle: milestones, launches, monitoring, maintenance, and iteration on product-market fit.
The Inner Loop
Each phase of the inner loop has a different cost distribution and benefit scaling, and the rational response depends on where it falls in the framework.
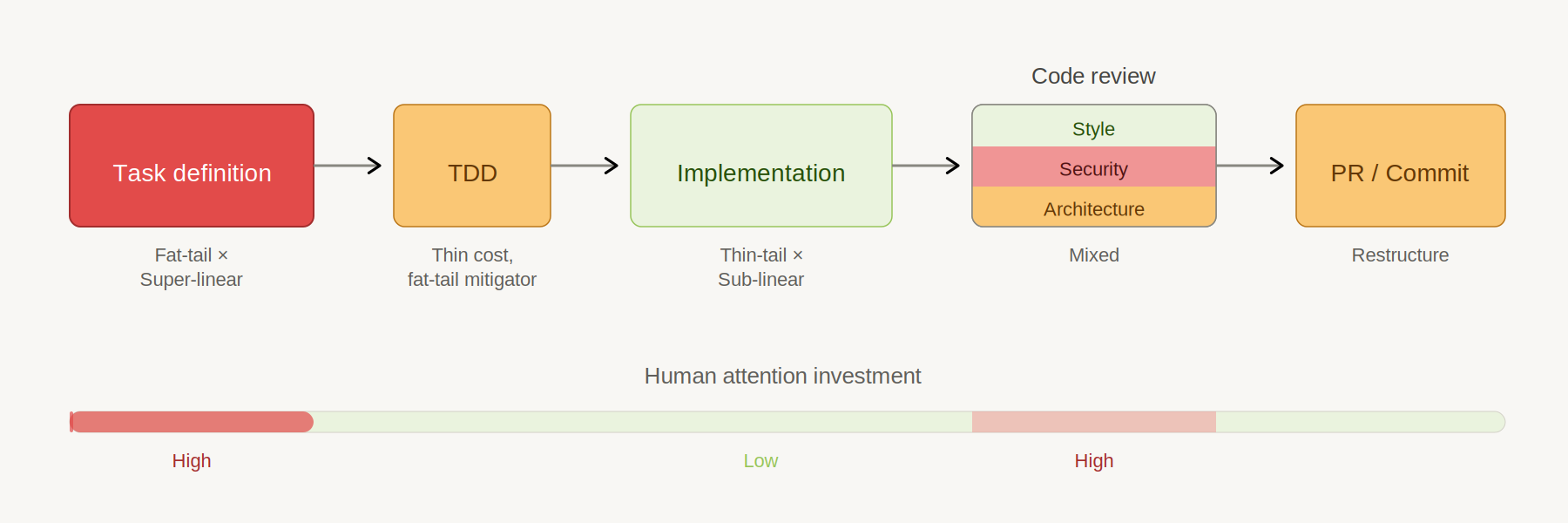
The inner loop, classified. Human attention concentrates at task definition and security review. Everything in between is increasingly automated. Image: Claude Opus.
Task definition
Task definition is where the inner loop begins, and it’s where the highest-leverage human judgment lives. Everything downstream depends on getting this right.
The costs here are fat-tailed. Wrong requirements waste everything downstream, and the distribution of outcomes is heavily skewed. A feature nobody wants costs the same to build as a feature everyone wants, so most bad specs produce moderate waste while a few produce catastrophic waste. The symmetry of build cost paired with the asymmetry of build value is what makes this phase so dangerous.
Good specs compound, which means the benefits scale super-linearly. Each well-defined task establishes patterns, vocabulary, and constraints that make subsequent specs more effective. Ondrejka captures this in Principle 10 of the manifesto: “Code the Constitution.” When your specifications are precise enough to serve as constitutional constraints, every downstream agent inherits that precision; the returns grow with each iteration rather than diminishing.
This is the new bottleneck, and the evidence is accumulating that it always was. An Agoda study covered by InfoQ found that AI coding assistants haven’t sped up delivery because “coding was never the bottleneck.” The bottleneck was always upstream: knowing what to build and why. AI can help research, explore, and draft, but the human must decide. The rational response is maximum human investment.
I’ve lived this. My most productive sprints start with a good RFC that makes it easy to decompose a project into tasks, sequence them, and tackle them systematically. At Delphos Labs, we don’t even write task descriptions by hand anymore; we have an agent skill that uses the Jobs to be Done framework to break work into well-scoped issues. The full text of the doc gets boiled into jobs, and those jobs map to parallel or stacked worktrees using git-spice for managing dependent branches. We also now have specific blocks of time each week where we review issues in triage, which means the quality of task definition gets its own dedicated attention rather than being squeezed in between other work. The quality of the agent’s output is entirely downstream of the quality of these inputs.
Test-driven development
TDD has an unusual cost profile: thin-tailed to produce, but fat-tailed in what it catches. AI writes tests well, especially end-to-end tests derived from specs, so the cost of producing tests has collapsed. But TDD’s real value isn’t in the writing; it’s in the verification layer that catches catastrophic problems before deployment.
The benefits scale super-linearly up to a threshold, then diminish. Going from zero to 80% coverage is enormously valuable because each new test covers previously invisible failure modes. Going from 95% to 99% has diminishing returns for most systems, where the remaining gaps are edge cases that rarely compound.
The cost dropped but the benefit stayed the same or increased, which makes TDD one of the clearest positive-ROI shifts in the new workflow. Kent Beck calls TDD a “superpower” with AI agents, and he’s right; it’s the sole reliable feedback mechanism when you’re not reading every line of implementation. Schluntz goes further: “the only part of the code I’ll read is the tests.” Andrea Laforgia’s T*D framework formalizes the same insight, and Ondrejka’s Principle 2 puts it bluntly: “vibes are not tests.”
Tests become the primary artifact the human cares about. Not the implementation. The tests.
Testing infrastructure
The shift from unit tests to integration and end-to-end tests sounds simple in principle, but it creates a serious infrastructure problem. If you want to test the real thing instead of proxies, you need the real thing to exist in a testable form. That means standing up your full application stack in a way that’s portable, reproducible, and fast enough to run on every PR.
The testing pyramid, with its wide base of unit tests, is giving way to what Kent C. Dodds formalized as the testing trophy, building on Guillermo Rauch’s widely quoted principle: “Write tests. Not too many. Mostly integration.” The insight is that unit tests often test proxies; mocked dependencies, isolated functions, synthetic scenarios that may or may not reflect how the system actually behaves. Integration and end-to-end tests, run against a real stack with tools like Playwright, test the thing your users will actually encounter.
The very best teams are investing in the infrastructure to make this possible. Ephemeral preview environments spun up per PR. Local Kubernetes clusters that mirror production. The portability principle is key: if you can stand everything up locally in k8s, that same configuration translates downstream into CI scripts, automated test suites, and staging environments. The investment compounds because each layer of automation builds on the one below it.
But this creates real architectural and design problems that consume real human time. If your product requires GPU inference, what’s the right way to make that work in a local k8s cluster? How do you mock or proxy the services that can’t run locally without losing the fidelity that made you switch to integration tests in the first place? How do you handle service dependencies that span teams or external APIs? These are fat-tailed design decisions; get them right and every engineer on the team moves faster for the life of the project. Get them wrong and testing infrastructure becomes its own bottleneck, which is exactly the outcome you were trying to escape.
The rational response is to treat testing infrastructure as a first-class investment in the bottom-right quadrant. It’s expensive to build, requires deep architectural judgment, and the benefits are super-linear; once the infrastructure exists, the cost of validating any change against the real system drops toward zero. The irony is that making tests cheap requires expensive human decisions about infrastructure.
Implementation
Implementation is where the cost collapse is most dramatic. Routine bugs, boilerplate, and formatting are all driving toward zero marginal cost. Schluntz estimates that the length of tasks AI can handle is doubling every seven months, which means the frontier of what counts as “routine” is expanding fast. The costs are thin-tailed and shrinking.
The benefits are sub-linear for commodity features and linear for novel ones. The tenth CRUD endpoint is worth less than the first because each additional one covers less new ground. But a novel integration or a prototype exploring a new hypothesis still returns proportional value, which is why the question of what to build matters more than ever.
The rational response is to let AI have it. This is the Jevons response in its purest form: since building is cheap, build things that previously weren’t worth building. This is Ondrejka’s point about building to answer questions and test hypotheses. The human’s job here is to decide what’s worth building, not to build it.
Code review
Code review has a clock-speed problem. Traditional code review is a human-speed process: a developer reads a diff, thinks about it, leaves comments, waits for responses. That cadence made sense when humans wrote all the code, because the production rate and review rate were roughly matched. But when agents produce code at agent speed, human-speed review becomes the bottleneck that throttles the entire system. Twenty-plus reviews a day is not a workload; it’s a denial-of-service attack on the reviewer’s judgment.
The Thoughtworks Future of Software Development Retreat reached the same conclusion: traditional code review must change because the volume of AI-generated code makes line-by-line human review physically impossible. Their participants proposed risk-tiering code by criticality, with different review intensities for different risk levels. Laforgia’s T*D framework points in the same direction, as does the Ship/Show/Ask model. The evidence is converging: code review as currently practiced optimizes for a world that no longer exists.
The data makes the mismatch quantitative. Bacchelli and Bird’s 2013 Microsoft Research study found that less than 15% of review comments relate to bugs, with the primary value being knowledge transfer. One organization in Laforgia’s analysis spent 130,000 hours waiting on PRs that received zero comments. Philip Su, writing about lights-out codebases, describes a colleague who landed 417 PRs in one day. The pull request was designed for open-source development, where untrusted strangers contribute to a shared codebase; in private teams with agent-generated code, the original design rationale doesn’t apply.
The risk-return framework clarifies where human time should go instead. Style and logic review is thin-tailed cost, sub-linear benefit, highest volume; it should be fully automated through AI reviewers, linters, and CI gates. Security review is fat-tailed cost and super-linear benefit, because a missed SQL injection is catastrophic in a way a missed style violation never is. Veracode tested 100+ LLMs and found a 45% failure rate on OWASP Top 10 issues. Shukla, Joshi, and Syed documented a paradox where iterative AI code generation increases critical vulnerabilities by 37.6% after successive iterations. And slopsquatting, where attackers publish malicious packages under names that LLMs hallucinate as dependencies, is a novel attack vector that AI abundance itself created.
Architectural review follows Schluntz’s leaf-node versus trunk distinction: leaf node debt is thin-tailed and contained, core architecture debt is fat-tailed because errors propagate through the entire codebase.
The rational response is not to review faster but to review differently. What emerges is a bookend model with two clock speeds. At the front end, before any code is written, a kick-off review operates at human speed: architecture debate, security threat modeling, RFC writing, definition of done. This is where the trunk-versus-leaf distinction gets applied; the humans decide what’s core and what’s leaf before agents start building. At the back end, before anything ships, a launch review operates at human speed: structured checklists for security posture, data model integrity, observability, and access control. Work ships behind feature flags, RBAC boundaries, or similar isolation mechanisms so that the blast radius of any failure stays contained.
Between the bookends, code review runs at agent speed. AI reviewers handle style, logic, test coverage, and known vulnerability patterns continuously as code is produced. The volume problem disappears because agents reviewing agents is not bottlenecked by human attention. The security research cited above doesn’t go away; it means the agent-speed layer needs strong automated gates for known vulnerability patterns, not that humans should try to read every line. The human role in the middle layer is supervisory: monitoring agent verdicts, intervening on exceptions, and escalating anything that touches the boundaries defined in the kick-off.
This is where I’ve landed in practice at Delphos Labs. My agents review agents for most code. I step in for changes that touch shared abstractions, data models, or security boundaries. The remaining friction isn’t from reading code; it’s from context-hopping between agent verdicts, which is a problem the bookend model addresses by concentrating human judgment at two well-defined moments instead of spreading it across every diff.
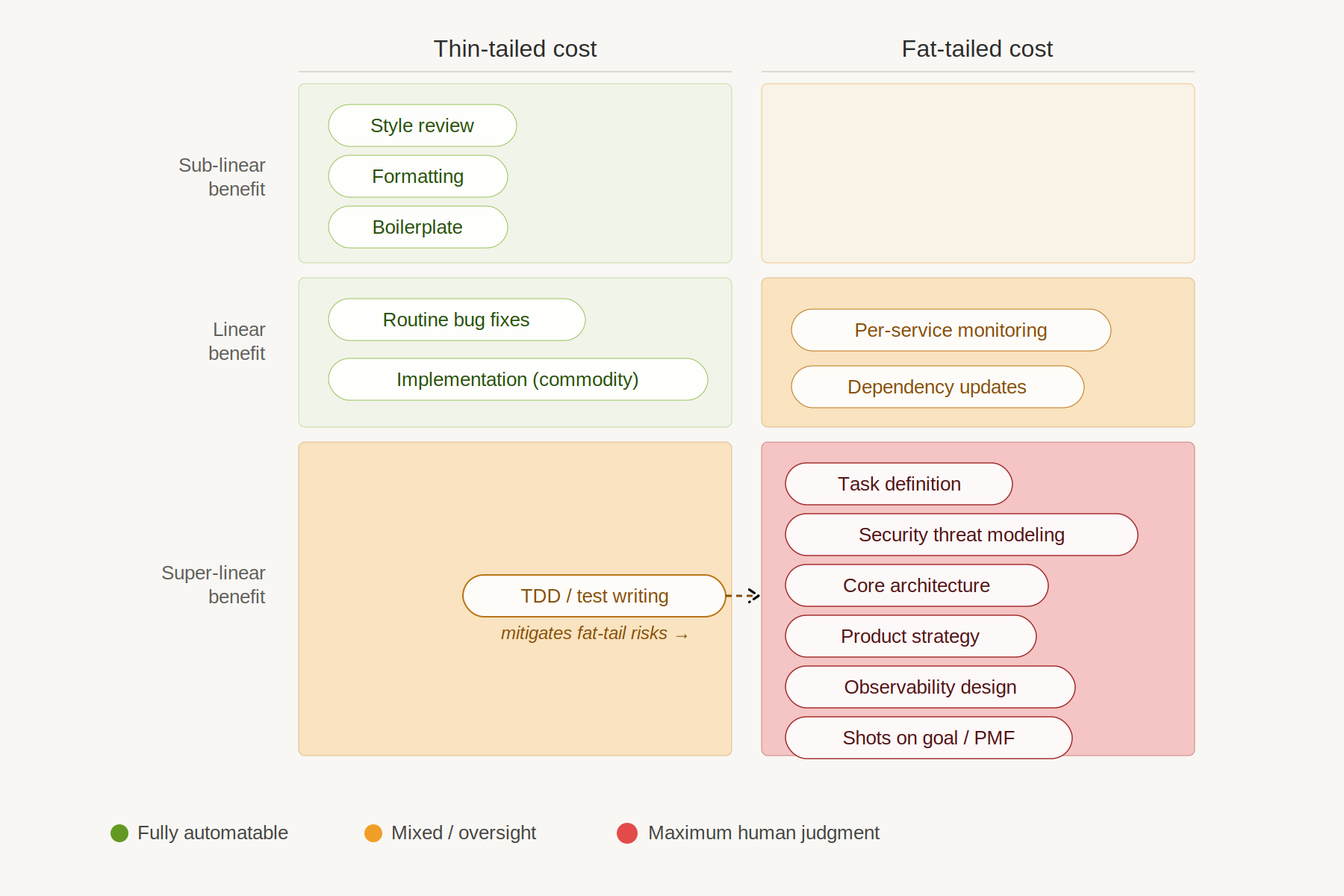
Every SDLC phase classified. Green dots are fully automatable. Red dots demand maximum human judgment. TDD is cheap to produce but catches fat-tailed risks, earning its place near the center. Image: Claude Opus.
The Outer Loop
The inner loop is where most of the abundance conversation lives, because that’s where the cost collapse is most visible. But the outer loop is where the fat tails concentrate. Tal Hof documents the dynamic playing out right now: GitHub pushes are up 35% year-over-year, new iOS apps up 50%. Cheaper software means more software gets built, which means more code to evaluate, deploy, monitor, and maintain. Milestones, launch cycles, monitoring, iteration on product-market fit: these phases carry the highest leverage precisely because they resist automation. The costs are fat-tailed, the benefits are super-linear, and human judgment is not a bottleneck to be removed but the product itself.
Shots on goal
When building is expensive, organizations bias toward approval. A shot that costs months of engineering time needs to be right, so the incentive is to say yes at the end, to justify the sunk cost, to ship what you built even if the evidence is mixed. Cheap iteration inverts this. When a shot costs days instead of months, you can afford to be honest about what you learned, kill what isn’t working, and try again with the next hypothesis.
Delphos Labs is trying to adopt this mentality. Our CTO Caleb Fenton often reminds us that everything is a draft that we can rewrite and make better. We’re doing what we can to learn from shots: producing post-mortems, extracting lessons for future designs, treating each attempt as an input to the next one. The learning compounds across attempts, and faster iterations mean the lessons accumulate before the market moves on.
Our willingness to experiment shows in ways that would have been unthinkable at the old velocity. The first version of our product was written in Python, because Python is a great language for humans. We rewrote the whole thing in Rust in a sprint that took a couple of weeks. In a non-agent world, this is a crazy thing to do. You would need to get people up to speed on a new language. You might have to hire and fire. The costs might get so high that the rewrite never happens at all, and you live with the performance limitations forever. But when the agent knows Rust and humans are spending their time on architecture, security, and product direction rather than writing code, the calculus changes completely.
The economics reinforce the intuition. Product outcomes follow a power-law distribution; most attempts fail, a few succeed enormously. The rational response to power-law outcomes is to maximize the number of attempts, because each attempt is now cheap. Imagine shipping three prototypes in a quarter that you never would have attempted at the old velocity. Two go nowhere. One becomes a core feature. That’s the math of super-linear returns: the expected value of the third attempt includes everything learned from the first two.
The Rust rewrite isn’t even the biggest bet. Delphos Labs is in the middle of a significant architectural pivot right now, rethinking core product focus and rebuilding around an agent-native architecture. Concept to working POC on secure infrastructure took about a month. The building is fast. The hard part is the customer conversations, the market read, the strategic judgment about which direction to commit to. That friction is real and irreducible, and it’s exactly where the framework predicts human time should concentrate. The teams shipping fastest aren’t necessarily winning. The teams learning fastest are.
Monitoring, observability, and maintenance
On a recent episode of The Ezra Klein Show, Jack Clark described how Anthropic is practicing fat-tail reallocation. Engineers who used to write code now build dashboards, measurement systems, and monitoring tools for AI agents. The work moved from production to observation.
The reason monitoring matters this much is that maintenance is the dominant lifecycle cost. The 60/60 rule from Pressman’s Software Engineering is the canonical reference: 60% of lifecycle costs are maintenance, and of that, 60% is enhancements. But the individual maintenance tasks, from bug fixes to dependency updates to routine refactoring, are thin-tailed and increasingly agent-speed work. Google’s AI migration system submitted 93,574 edits across 39 large-scale code migrations over twelve months, with 87% of generated code committed without human modification. The individual fix is cheap. Monitoring is what ensures the right fixes get found, prioritized, and validated. It’s the system that keeps maintenance costs thin-tailed instead of letting them drift fat.
At Delphos Labs, we’re building toward this, and the shape of it is worth describing because it illustrates how much of the operational loop has already collapsed into a single interface. We have PagerDuty integrated into Slack with an AI agent that reviews and assesses every alert; most of the triage work is done before a human sees it. When a Sentry alert fires, I tell an agent to use the Sentry MCP to diagnose, then log into production Kubernetes to find the failing job and pull logs. CI failures work the same way: point an agent at a failing branch and it figures out the problem. Triage, debugging, messaging, infrastructure inspection; all of it happens inside a single tool with a chat interface. The agentic world doesn’t just change what work costs. It changes where work lives. Operations that used to span five tools and three context switches now happen in one conversation.
And I’m still the bottleneck. Every one of these workflows runs through me, which means they run at human speed despite the tooling running at agent speed. The next step is obvious: agents responding to good monitoring close to instantly, with minimal human intervention. Google’s migration system is already there for a specific class of maintenance work. The gap between “agent diagnoses the problem” and “agent fixes the problem autonomously” is closing fast, and when it closes, the human role shifts from “respond to alerts” to “design the system that responds to alerts.”
But there are tensions. The DORA 2025 report found that surface metrics improve with AI adoption: faster lead time, higher deployment frequency. Meanwhile, Hivel.ai’s analysis found that a 25% increase in AI adoption correlated with a 3.1% improvement in review speed but a 7.2% drop in delivery stability. The metrics that are easy to measure improve. The metrics that matter for reliability degrade. The most likely explanation is that teams are optimizing for thin-tailed metrics like velocity while fat-tailed risks like stability accumulate unobserved. Monitoring works as a fat-tail mitigator only if you’re monitoring for fat tails.
The rational response is to invest in monitoring for the right things. Not deployment frequency. Stability, error rates, security anomalies, architectural drift. The fat-tailed judgment; what to maintain, what to deprecate, what to rewrite; stays human. A wrong deprecation decision can break downstream systems. A premature rewrite can burn months. But the system that surfaces those decisions, and that handles the thin-tailed fixes autonomously once the decision is made, is where the investment belongs.
What Stays Expensive
The bottom-right quadrant is the list of things that remain expensive regardless of how cheap software gets to produce. These are phases with fat-tailed costs and super-linear benefits: task definition, core architecture, security threat modeling, product strategy, and observability design. The common thread isn’t technical complexity. It’s judgment under uncertainty, applied to decisions with unbounded consequences.
Alex Imas, in “What will be scarce?”, offers the economic explanation. Drawing on a structural change model from Comin, Lashkari, and Mestieri, he argues that income effects, not price effects, drive 75% or more of observed sectoral reallocation. As commodity production gets cheap, spending shifts toward sectors with high income elasticity; what Imas calls the “relational sectors,” where human involvement is part of the product rather than a cost to be minimized. In the software development lifecycle, those sectors are design, architectural judgment, security expertise, and customer understanding. These aren’t automatable because the human judgment is the product.
These are management skills. Ethan Mollick observes that “the skills dismissed as ‘soft’ turned out to be the hard ones.” My experience confirms it. The best weeks aren’t the weeks with the best code. They’re the weeks with the best task descriptions, the sharpest review criteria, the most thoughtful architectural guidance.
The boundary between quadrants isn’t fixed, and that’s part of the point. As AI capability improves, some fat-tailed work will migrate toward thin-tailed. Threat modeling may eventually become partially automatable; architectural review may get AI assistance that shifts it from “maximum human investment” to “AI-assisted, human-led.” The framework’s value isn’t in the current placement of phases. It’s in the discipline of reclassifying as capabilities shift, and in the recognition that some work will remain fat-tailed longer than most people expect.
Scaling the Framework
Everything I’ve described so far works because Delphos Labs is small and senior. The team is mostly staff engineers and above; everyone can hold the whole system in their head, make architectural calls independently, and serve as their own judgment layer for security and product direction. The risk-return framework maps cleanly onto each person’s attention budget. That’s not an accident. It’s the rational team structure for an agent-abundant world: hire for judgment, not for code production.
This breaks with people. Add a second engineer running agents in parallel and you’ve doubled the PR volume. You’ve also created a risk that didn’t exist before: two people making incompatible architectural choices simultaneously. At a team where everyone is senior, architectural coherence is cheap; shared mental models and high trust keep things aligned. Scale beyond that and coherence gets expensive. At fifty people, it’s the dominant cost.
Fred Brooks identified this decades ago. Communication channels grow as n(n-1)/2; double the team and you nearly quadruple the coordination overhead. AI abundance makes this worse, not better. If each engineer triples their output, a five-person team goes from five PRs a day to fifteen. The judgment calls don’t just triple; they multiply across every pair of engineers whose work might interact. The fat-tail surface area grows with the square of the team, not the size.
The reviewer alignment problem compounds this further. On a small senior team, everyone knows what “good” looks like because they helped define it. Scale the team and you need multiple people making these calls, each aligned on standards, calibrated on risk tolerance, consistent in judgment. Alignment is itself a fat-tailed cost. Two reviewers with subtly different mental models of what constitutes “core architecture” will make subtly different decisions, and the inconsistency compounds through the codebase over months. The cost of misalignment isn’t the individual bad decision; it’s the slow drift that nobody notices until the system is incoherent.
This is why Google invested so heavily in readability reviewers, style guides, and engineering standards. Not because individual formatting choices matter, but because consistency at scale prevents the fat-tailed cost of architectural drift. The thin-tailed part of that investment, style enforcement, can now be automated. The fat-tailed part, shared judgment about what good architecture looks like, cannot.
This is Hayek’s knowledge problem applied to engineering organizations. The knowledge that makes a senior engineer effective is dispersed, tacit, and resistant to centralization: what “good architecture” looks like in this specific codebase, which tradeoffs are acceptable, where the hidden dependencies live. James C. Scott draws a similar distinction between techne, formal knowledge that can be written down and transmitted, and metis, practical knowledge that comes from experience in a specific context. The challenge of scaling an agent-driven team is fundamentally a challenge of converting metis into techne fast enough that agents and new team members can act on it.
This creates a new imperative: get the knowledge out of senior engineers’ heads and into artifacts that agents can consume. Task specifications. Frameworks for defining tasks. AGENTS.md files that point agents toward the right context. A detailed organizational knowledge base of style guides, architectural decision records, and design principles. Tools that force agent adherence to this knowledge base; a big part of our code review process at Delphos Labs is getting the agents to correctly identify the relevant parts of the knowledge base for each review. And processes that get all of this regularly reviewed and updated, because codified knowledge rots faster than the intuition it was extracted from. Caleb has been clear that writing and maintaining these artifacts is one of the highest-leverage things he can do. There’s an old Google joke that captures the progression: SWEs code, Senior SWEs talk and code, Staff SWEs just talk. In an agent world, “just talking” is a formal version of solving the knowledge problem; the talking becomes specifications, frameworks, and standards that scale judgment beyond any individual.
An ETH Zurich study found that human-written AGENTS.md files improve agent task completion, while LLM-generated ones actually hurt performance. This is Scott’s point exactly: metis can’t be mechanically reproduced. It has to be genuinely extracted from practitioners who understand the context. The investment is expensive, it’s ongoing, and it’s irreducibly human. But it’s how you scale the bottom-right quadrant without losing the judgment that makes it valuable.
The risk-return framework still applies at any scale. Fat-tailed costs with super-linear benefits still deserve maximum human investment. What changes is the mechanism for ensuring human attention reaches the right places. At a small team, the mechanism is personal judgment; you see everything, you decide. At a medium team, the mechanism is process design: review routing that escalates architectural changes to senior engineers, security gates that flag high-risk patterns, shared standards documents that encode the team’s collective judgment. At a large organization, the mechanism is organizational structure. Conway’s Law predicts that your system’s architecture will mirror your communication structure. The risk-return framework predicts something more specific: your org structure determines which fat-tailed risks get human attention and which ones slip through the cracks.
But there’s a more radical implication. If agents make code cheap and human coordination is the binding constraint, then large organizations with deep bureaucracies are structurally disadvantaged. Every approval chain, every cross-team alignment meeting, every committee review is human-speed friction that agents can’t accelerate. The Innovator’s Dilemma has always described why large incumbents struggle to pivot; the costs of coordination, the weight of existing customers, the politics of resource allocation. Agents don’t solve any of that. They make the gap worse, because the small team that can pivot in a month is now competing against incumbents whose coordination costs haven’t changed. I saw this dynamic firsthand at Google during the Gemini transition; the technical capability was there, but the organizational machinery moved at its own speed. The rational organizational response may not be “add agents to existing teams” but “restructure toward smaller, more autonomous units” so that human time concentrates on judgment rather than coordination.
The highest-leverage role shifts accordingly. At Delphos Labs, the highest-leverage decision was building a senior-heavy team where everyone can operate as an independent judgment layer. At a larger organization, the highest-leverage person is the one who designs the system that ensures the right architectural calls get made, regardless of who makes them. That’s the difference between being a good engineer and being a good engineering leader. And if the bottom-right quadrant is where human judgment matters most, then hiring for it is the highest-leverage organizational decision: not “who writes the best code” but “who has the best judgment about architecture, security, and risk.” These are senior skills, experience-dependent, and AI abundance makes them more valuable, not less.
Conclusion
The engineers who thrive in this environment will reallocate their time toward fat-tailed, super-linear work; the teams that thrive will accelerate the outer loop, taking more shots on goal while paying the taxes on security, architecture, and observability that abundance demands.
The structural changes run deeper than individual productivity. Code review is splitting into two clock speeds: human judgment at the bookends, agent speed in between. Organizations that can pivot in a month are structurally advantaged over those whose coordination costs haven’t changed. The knowledge that makes senior engineers effective, the metis that lives in their heads, becomes the critical bottleneck, and the teams that invest in extracting it into specifications, frameworks, and standards are the ones that scale without losing judgment.
Three times the PRs is not the end state. It is the beginning of learning which frictions are load-bearing and which ones were only ever artifacts of scarcity. The work does not disappear. It moves to the places where getting it wrong has unbounded downside and getting it right compounds. That is where the humans belong.
The exponential makes thin-tailed work vanish. It does not make fat-tailed work vanish; it makes fat-tailed work more consequential, more urgent, and more human. Schluntz’s closing observation stays with me: “Remember the exponential. It’s okay today if you don’t vibe code, but in a year or two, it’s going to be a huge disadvantage.” He is right about the exponential. The question is what you do with the time it frees up.
Tools Used
- OpenCode with Claude Opus 4.6 for drafting, research, and editing
- Claude Opus 4.6 in the Claude Desktop app for diagram generation
- ChatGPT was consulted on the choice of a header image for the article
- Sources listed in the annotated bibliography