

LLMs provide a general model for knowledge work
Introduction
I’ve spent a couple of articles talking about working with agents and how access to tools can make them better. This one is going to be a little different. Today, I’m going to discuss something more conceptual. Since I’ve been working regularly with agentic development tools, I’ve started to realize that basic dev workflow is everywhere. And since this basic workflow is at the heart of knowledge work, I believe that it’s a great indicator about where we can expect AI to both impact and improve professionals.
A big inspiration for this is Mukund Sundarajan’s Thinking Like a Large Language Model, which I was lucky enough to catch early versions of while still at Google. Mukund’s book is excellent for helping build a mental model for how LLMs exhibit so many capabilities that we are already beginning to take for granted. In the final chapter of the book, Mukund discusses how LLM’s can be interacted with in a manner similar to an employee: you are the manager of the LLM. In that chapter, he shows how with good enough guidelines, even relatively early models could produce excellent work, and code in particular, with feedback and correction. As he writes, “We could say that the role of the human is to bridge the gap between what the model thinks of as good, and what we think of as good, to bridge the gap between what use/misuse may occur in the real world, versus what the model thinks is possible, to bridge the gap between the true intent of the request and what the model interprets.” We’ll take this as the jumping off point for the rest of the article.
The model
The workflow in question is a basic loop. There are a few different ways to describe the steps. I’ll go with the perception, reasoning, action and adaption loop. It’s fleshed out in more detail in this post by Alexandr Bandurchin. Here is a diagram.
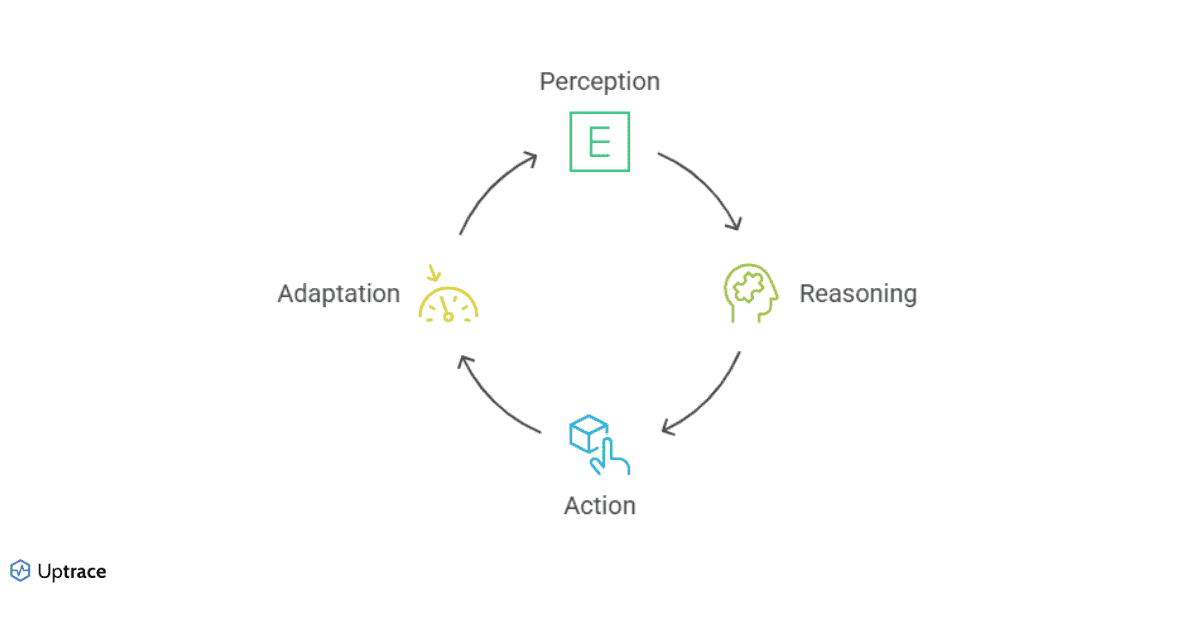
Since this is such a simple loop, there are many similar versions that you’ll find: perception, reasoning, action is somewhat common in robotics. Nonetheless, I hope you can see how this maps to the process of agentic development:
- perception: The user’s prompt, task guidelines and provided context define a task for the agent to complete. In short, this is the context step of the task
- reasoning: The agent establishes a plan to complete the task, including the use of external tools
- action: The agent uses the LLM’s innate abilities, like code generation, to complete the task
- adaption: With feedback, the agent either accepts the work, automatically corrects or takes user input to take the task on again
It should be clear that we, as guides of the agent in the process, serve two key roles. First, we are the ones defining the task, building the context needed and establishing guidelines. Claude is getting much better at understanding code, and can do phenomenal things with tools like ast-grep, but there are still limitations to generic search. Claude has a limited context window and can get sidetracked, especially on longer tasks. It is far more effective when given areas to focus its attention and examples to follow.
Our second role is described by Mukund’s quote above, to serve as the quality bar that Claude must pass for each iteration of work to be accepted. The most basic version of this, for agentic development, is to serve as a reviewer for every diff of code produced. This role is critical, and it is why Anthropic recommends regularly interrupting Claude to course correct. Like working with an employee, again to borrow Mukund’s metaphor, good feedback is often crucial in order to get an excellent result.
Building better context
I’ve spent a couple of articles already thinking about context engineering already, but given the wealth of material available it’s worth another pass. If you haven’t read those, it’s worth returning for a second to the describing context by Phil Schmid:

We have a lot of ways to apply these different forms of context. One great example is in this repo by Cole Medin. He points out that a good workflow:
- Maintains global standards and rules in a
CLAUDE.mdfile - Builds an initial task description in a structured manner, following a template; Cole calls this an initial featured request
- Turns this request into a series of steps and prompts based on codebase and external research; other places call this something like a scratch pad and regular Claude users should have seen its own TODO system by now
- Proceeds stepwise to through task
You can think about each of these as their own workflow loop, and building the context can be its own iterative process where you provide feedback
- Global standards evolve after noticing edge cases during project development, with PRs regularly generated to update our team and project Claude files
- The structured request can be developed over multiple conversations, relying on the model’s short-term memory to build up the information that will eventually be translated into the template
- Similarly, the actual implementation should be reguarly assessed and updated before beginning work
It’s also important to remember that all features of agents can be involved in developing the later context:
- Cole’s workflow mentions external research; this can come from RAG tools or web search tools
- Command-line tools, like the previously mentioned ast-grep are especially helpful for working on large codebases
- As are other forms of longer-term memory, like directory README’s and other code pointers
While it’s already been suggested above, it’s also important to emphasize that this first step in the workflow, context building, can generate and store various artifacts that can be saved for later. At Delphos, the structured request is developed over conversations with a model and stored as issues in Linear. Linear has templates that we use to provide structure to Claude, and it gives us the ability to better plan, estimate and triage the work that we define over these cycles. We also have an extensive catalog of docs in Notion, which is also accessible via MCP.
Being able to correctly establish how the task is meant to be accomplished is just as crucial for the human user when working with AI. My periods of lowest productivity when coding with Claude are all tied to me not knowing what I was doing. Claude has an ability to read faster and searcher deeper than I could ever be capable of, and it’s clear that you are incentivized to go faster when using the model. And yet, context is king. Having tools to summarize a problem and light a map through solutions makes sure that I can successfully guide the AI to a good outcome.
Ever more sophisticated feedback
Become a better Claude reviewer
In Seeing Like an LLM, Rohit Krishnan points out that many of the weirdest aspects of LLM behaviors are tied to a lack of context. As he writes,
We learn that frontier LLMs act according to the information they’re given, and if not sufficiently robust will come up with a context that makes sense to them. Whether it’s models doing their best to intuit the circumstance they find themselves in, or models finding the best way to respond to a user, or even models finding themselves stuck in infinite loops straight from the pages of Borges, it’s a function of providing the right context to get the right answer. They’re all manifestations of the fact that the LLM is making up its own context, because we haven’t provided it.
While we talked about context as an earlier part of the loop in the previous section, feedback plays just as important of a role in establishing the guidance that models need in order to achieve the goals set in front of it. Since work is almost always iterative, feedback from previous steps helps build the context for future work.
The most obvious source of feedback is from the user. When working with Claude, by default each change is presented for your review, in a diff, before it is applied. It’s your choice to accept the diff or give Claude a correction about how to proceed. One of the great design choices for Claude is how these interruptions are both built in and recommended. As Anthropic mentions in their Claude Code guide:
you’ll typically get better results by being an active collaborator and guiding Claude’s approach. You can get the best results by thoroughly explaining the task to Claude at the beginning, but you can also course correct Claude at any time.
This is one of the biggest changes that AI coding demands on a developer: you spend a lot more time reviewing code than you do actually writing code. For those of us who worked in a tech company for awhile, it’s not that abrupt of a transition. Professional Software Engineers and leads in particular, spend a lot of time reading and reviewing code. Getting better at this is often a function of time spent on the job. At the same time, there are a lot of really good guides out there, often written with peer review in mind. I’m biased towards Google’s.
As a reviewer, you are responsible for the quality of the particular diffs, but also for creating memories, as Anthropic calls it, that Claude will reference in future sessions. This shortcuts the common blank slate problem. With extensive enough guidance on you expect work to be completed, you reduce the amount of context that you will need to provide Claude for each new effort. Claude even gives you a shortcut for this: # followed by a command will be saved to memory. Again, this isn’t necessarily all that surprising for professional Software Engineers. Every organization has a language-specific style guide; here’s Google’s Python guide. And most larger organizations have extensive knowledge bases covering best practices; here’s Google’s tips for C++.
As we transition to ever more code written by LLMs, translating this massive knowledge base into a form LLM’s can keep in context remains one of the great challenges for us to take on. Ever large context windows will help, but we will also need tooling-solutions to make this kind of deep knowledge more available to models.
Use tools and tests
While the user remains the first line of feedback, there are some notable drawbacks to prompts, memories, etc. They will all rely on a model’s ability to instruction follow, and adherence will never be perfect. Again, the practice of software engineer provides a good example: No software engineer is able to perfectly follow guides and best practices on their. Instead, we built tools to automate all of this: formatters, linters, pre-commit checks and more.
Claude can automatically use tools too, and there are two easy routes to get perfect adherence. The first of these is through hooks, which create automatic commands that will run after specific Claude events, like the beginning of a session, after a tool is used, etc. One great design choice for Claude is that editing a file is considered a tool use, which makes it very easy to apply a tool right after a file changes. For example, here’s how you run ruff format to make sure your Python formatting is correct.
{
"hooks": {
"PostToolUse": [
{
"matcher": "Write|Edit|MultiEdit",
"hooks": [
{
"type": "command",
"command": "uv run ruff format ."
}
]
}
]
}
}
You could extend that hook to check for lint errors, verify types, etc. In practice, this ends up feeling a lot like standard editor behavior, like format on save. In the same vein, if you have many of these tools already set in your editor, Claude will pay attention to these checks if connected to an open session. As my previous post on this mentioned, a pretty common workflow is to start Claude within the integrated VS-Code terminal. It will set up everything you need this first time. You can choose to use a separate terminal in the future; use claude --ide to connect. All diagnostics will be shared after the connection is created.
Tools provide immediate feedback on syntax and formatting, but tests are required for true checks of code correctness. Once again, this is something explicitly called out in the Anthropic guide. By starting with tests and the expected outcomes for the task first, you give Claude a great source of feedback to follow as it completes its work. Even better, Claude will automatically run tests, check for failures, debug particular cases, as long as you give it the appropriate permissions.
The testing loop can start small, with unit tests for particular behaviors you want to check in your code. It can grow progressively more complicated as the system grows, covering integration tests, integrating with MCP tools to check output in the browser, and so on.
Does this sound familiar?
Software engineering is one of the best places to understand this type of loop, but they are in fact everywhere in knowledge work:
- Doctors build context when they diagnose symptoms in a patient, they receive short-term feedback in follow ups and long-term feedback through various studies
- A day trader builds context studying an industry and gets feedback from market behavior
- An accountant compiles data across many different sources when preparing financial statements, which have both internal consistency checks and external audits to ensure their correctness
- A engineering manager’s job within an organization is geared towards understanding current status and context building, and they get feedback through metrics tied to work completion
- An AI consultant (and I know a good one if you want one) gets context through an introductory call and audit of a business, and gets feedback through particular projects
Tyler Cowen has a famous maxim for all of this: Context is that which is scarce. Persuasion, education, research and many more fields are driven by the acquisition of context that people can effectively leverage. This only becomes more true when applying AI to various forms of knowledge work. Can you translate a lot of the process into forms of knowledge that the AI can leverage? You’ll probably get quite far.
And at the same time, the great frontier in AI development remains effective feedback. Rohit Krishnan recently shared some experiments on getting an LLM to write Tweets, and he hit a wall because effective feedback for good writing is still quite hard. Automatic signals to apply to writing are still scarce. As he writes:
The next few years are going to see an absolute “managerial explosion” where we try to figure out better rubrics and rating systems, including using the smartest models to rate themselves, as we train models to do all sorts of tasks. This whole project is about the limits of current approaches and smaller models. When GPT-5 writes good social posts, you can’t tell if it learned general principles or just memorized patterns.
Data scientist workflows in this loop
I swear, this is a Data Science blog, but I realize that we haven’t been talking much about Data Science recently. Well, here’s a good time to start discussing it.
First and foremost, much of Data Science work follows the knowledge worker loop that we’ve been discussing. This is most obvious when Data Scientists work as statistical consultants:
- Context is built by understanding a particular client’s business needs and aligning that with known statistical algorithms; you can see flavors of that in https://allendowney.blogspot.com/2011/05/there-is-only-one-test.html
- Feedback comes from observing many cases of the same experiment, and checking a procedure’s calibration or a confidence interval’s coverage
Even though a lot of the Data Science workflow follows the same loop structure discussed above, there is an additional special role that Data Science occupies in AI work: beyond the smaller correctness checks above, Data Scientists create the higher order feedback loops that we need for effective development and applications of AI. The next generation of Data Scientists will be experts in providing signals that can be leveraged for improving AI systems.
The most fundamental of these is through model eval. Developing evals has become an academic and big tech specialty, but this skill will diffuse with the application of AI to different domains. There are already dozens of platforms available for AI eval, across a range of qualities
- Primarily human-eval focused companies like Scale, Surge, Mercor and Labelbox are likely the best routes for high quality data for evals, but they are without a doubt also the most expensive
- Most major AI platforms, include Vertex AI and Azure, offer some form of eval, and there are literally dozens of startups trying to automate this process
Both sides of the coin run into similar problems: doing evals well is very hard. Pushing frontier capabilities requires a lot of expertise, and the entire process can be quite noisy. Human data workers make mistakes; models hallucinate. And the companies do this well bring a depth of operational expertise that is often quite impressive. I discussed some of the measure challenges with Google colleagues in Measuring Validity and Reliability of Human Ratings.
Other key Data Science skills form the core of feedback, especially for organizational level decision making. Is the new feature actually making the product better? Well, that’s what experiments are for, and Google Data Science helped write the textbook on this. Similarly, classic data analytic skills, maybe supplemented by AI, are needed for building good metrics, forecasting organizational outcomes and driving progress.
Where this is going, or what the model is lacking
The model for knowledge that I’ve discussed in this article is far from perfect, but let’s hope at least that it’s useful. One of the biggest gaps from humans is in the capacity to learn. Humans almost always get better at a task the more they do it. Current AI systems do not. This has become a somewhat hot topic lately, with Dwarkesh calling online learning the largest impediment to AGI and Andrej Karpathy mentioning it as a key issue in better agentic systems:
I am bullish on environments and agentic interactions but I am bearish on reinforcement learning specifically. I think that reward functions are super sus, and I think humans don’t use RL to learn (maybe they do for some motor tasks etc, but not intellectual problem solving tasks). Humans use different learning paradigms that are significantly more powerful and sample efficient and that haven’t been properly invented and scaled yet, though early sketches and ideas exist (as just one example, the idea of “system prompt learning”, moving the update to tokens/contexts not weights and optionally distilling to weights as a separate process a bit like sleep does).
Not to get too far ahead of myself, but much of the point of the post has been about solving the problem through complementarity. Human’s can figure out how to guide the LLM better, and human’s can manage long-term context, like system prompts, to make the model better in future iterations. While this demands pair systems instead of pure agents, there’s no doubt that this is a useful route forward for getting mundane utility from new models.
In a similar vein, we are still only at the beginning for building organizations that effectively leverage all of our new capabilities. Certainly, education for individual contributors is a start. Hopefully this blog post starts pointing there. But there are all sorts of open questions about designing workflows that increase productivity and measuring the effectiveness of AI-human paired employees once these workflows are in place. I hope to take that on further in a future blog post.
Tools Used
- Gemini was used both for research and as my editor